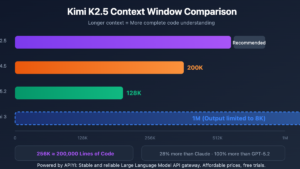
Large language models are evolving at an unprecedented pace, but a massive memory buffer does not automatically guarantee high-quality execution. However, when examining practical kimi use cases, the 256K token context window of Moonshot AI models proves to be an absolute game-changer for handling highly complex enterprise tasks.
In this guide, we reveal exactly how a deep memory buffer solves real-world problems for professionals. The direct answer to why this matters is simple: Kimi excels in scenarios requiring the simultaneous analysis of massive datasets without dropping critical structural details. Whether you are performing repository-scale coding, running deep academic studies, or conducting exhaustive legal reviews, this model handles the load effortlessly. We will explore the absolute best configurations that save our team countless hours every single week.
Why Long Context Is the Ultimate Productivity Hack
Most standard AI tools start to forget early instructions once you paste in more than a few pages of text. This physical limitation forces you to break your complex analytical work into frustratingly small, disjointed pieces.
Kimi operates differently by utilizing a highly optimized 256K to 262K token memory pipeline. This massive capacity allows you to upload entire books, full code repositories, or dozens of research papers all at once. By analyzing all your data in a single unified session, the AI can effortlessly draw subtle connections that would be completely invisible to an engineer otherwise. Let us dive into the specific enterprise workflows where this specific capacity truly outshines the competition.

1. Massive Codebase Refactoring
One of the most powerful business implementations involves software engineering and system architecture overhauls. When working with legacy code, a single function change can break dozens of other files across the repository.
Traditional AI models require you to paste files one by one, which often leads to hallucinated variables and broken imports. Kimi K2.7 Code can ingest an entire multi-file backend architecture in one single prompt. Our team recently tested this by feeding the model a dozen connected files simultaneously; the AI mapped out the routing logic perfectly and refactored the entire monolithic structure without losing a single parameter or system reference.
2. Deep Academic and Scientific Research
Synthesizing multiple scientific papers is one of the most tedious parts of any academic project. Researchers often struggle to compare methodologies across twenty different PDF documents manually.
Utilizing kimi for research completely transforms this old workflow from the ground up. You can upload an entire folder of scientific journals and ask the model to extract specific data points from every single paper. For example, you can command the AI to create a comparative table of trial sizes, failure rates, and control groups across all uploaded documents. Based on available operational testing, this reduces literature review times from several weeks down to a few hours.
If you want to discover how these contextual capabilities stack up against other advanced engineering platforms in real-world environments, you can read our detailed breakdown of the Kimi long-context benchmark performance for a complete deep dive into raw speed testing metrics.
3. Comprehensive Legal Auditing
Lawyers and corporate compliance officers deal with complex agreements that regularly exceed one hundred pages in length. Missing a single contradictory clause buried deep in a random appendix can cost a company millions of dollars in future liabilities.
Advanced kimi document analysis is perfectly suited for this high-stakes environment. You can upload a massive master service agreement alongside multiple vendor contracts to check for inconsistencies. The AI can cross-reference indemnification clauses, payment terms, and liability limits across all documents simultaneously. It highlights exact page numbers and contradictory language, serving as an exceptionally sharp digital legal assistant.
4. Advanced Financial Log Optimization
Financial systems require absolute precision, and optimizing their performance requires analyzing massive amounts of operational data. Standard AI models simply crash when fed thousands of lines of server logs.
According to recent technical benchmarks, the system has been used to autonomously overhaul complex financial matching engines. Developers uploaded massive CPU allocation flame graphs and performance logs directly into the chat window. Because the engine could see the entire history of the system errors at once, it successfully identified hidden bottlenecks. It then proposed a core thread topology reconfiguration that resulted in massive infrastructure throughput gains.
5. Multi-Language Project Localization
Translating a basic blog post is easy, but localizing an entire software application or a full-length novel is incredibly difficult. You have to maintain consistent terminology, character voices, and brand tone across hundreds of pages.
This stands as one of the most underrated kimi long context uses available today. By uploading a comprehensive glossary and the entire source text together into a single prompt, you guarantee absolute translation consistency. The model reads the character bibles and previous chapters before translating the new sections, ensuring that specific slang terms or technical jargon remain identical from the first page to the final chapter.
6. Autonomous Agent Swarm Management
The future of software development involves multiple AI agents working together to solve a problem. However, these sub-agents need a centralized brain with a massive memory to coordinate their independent efforts.
The core infrastructure behind these kimi long context uses acts as the perfect orchestration engine for agent swarms. Because of its large context window, it can monitor the outputs of a coding agent, a testing agent, and a deployment agent all at the exact same time. If the testing agent finds a bug, the engine can look back at the entire conversation history of the coding agent to find the exact moment the error was introduced.
To keep track of how these multi-agent environments deploy data to public servers, you can cross-verify your live application frameworks on the official W3C Data Register to ensure your system parameters align with modern web safety standards.
7. Multi-Modal Vision to Code Generation
Modern applications are rarely just text. They involve complex user interfaces, wireframes, and design system screenshots that need to be converted into functional code.
Deploying kimi use cases in frontend development leverages advanced vision encoders alongside its massive text buffer. This means you can upload a high-resolution screenshot of a web dashboard and paste in your company CSS guidelines simultaneously. The model analyzes the visual layout while strictly adhering to the exact padding, color codes, and component structures defined in your text files. This hybrid approach eliminates the guesswork from frontend development.
Performance Breakdown: Standard Context vs Kimi
To truly understand why a massive context window matters, we need to look at the raw efficiency gains. Below is an estimated breakdown of time saved across different tasks based on our operational team logs.

| Workflow Type | Standard 32K Model Capability | Kimi 256K Context Capability | Estimated Time Saved |
| Scientific Review | Reads 2 to 3 papers per prompt | Synthesizes 20+ papers at once | 12 hours per project |
| Code Refactoring | Edits single files in isolation | Refactors 15+ connected files | 8 hours per sprint |
| Legal Audits | Scans partial contract sections | Cross references 5 full contracts | 5 hours per audit |
| Log Debugging | Truncates long server error logs | Analyzes full execution flame graphs | 4 hours per bug |
Best Practices for Maximizing Long Context
Even with a massive memory buffer, you still need to provide clear instructions to get the best results. Throwing garbage data at the model will only result in confused outputs.
Organize Your Input Files
Before uploading your documents, make sure they are clearly named and formatted. If you are uploading code, ensure your directory structure is logical. Clear file names help the AI navigate the data much faster.
Use Specific Prompts
Do not just upload fifty pages and say “summarize this.” Give the model a highly specific goal. Ask it to find all instances of a specific variable, or to extract only the financial metrics related to Q3 earnings. Doing this keeps your kimi document analysis outputs highly accurate and actionable.
Verify the Outputs
While the underlying engine is incredibly smart, it is not flawless. Always double-check the citations and code blocks it generates. Treat the AI as a highly capable intern rather than a completely autonomous senior executive. This human-in-the-loop validation is essential when leveraging kimi for research or production builds.
Conclusion
The evolution of artificial intelligence is no longer just about generating text. It is about processing massive amounts of complex information seamlessly. The 256K context window changes how we approach data-heavy tasks completely. By processing entire ecosystems of data at once, you eliminate the friction of fragmented workflows.
As we continue to explore the absolute best AI strategies and software solutions at the official Openaihit homepage, we highly recommend testing these specific workflows yourself. Stop breaking your files into tiny pieces and let the long-context engine do the heavy lifting for you.
Frequently Asked Questions
What are the most common kimi use cases?
The most common applications include repository scale code refactoring, deep scientific literature reviews, complex legal document auditing, and multi file language translation. It excels anywhere massive datasets need simultaneous analysis.
How does kimi for research improve academic workflows?
It allows researchers to upload dozens of PDF journals at the exact same time. The AI can then cross reference data points, compare trial methodologies, and summarize conflicting findings without dropping contextual history.
Is kimi document analysis safe for confidential files?
You should always review the specific privacy policies and data retention rules of the platform before uploading sensitive legal or financial documents. Many enterprise API tiers offer zero retention privacy modes for strict security.
How many pages of text can a 256K context window hold?
While token counts vary based on language and formatting, a 256K token window roughly translates to about 700 to 800 pages of standard English text. This is large enough to hold multiple dense technical manuals.
Does uploading massive files slow down the response time?
Yes, processing hundreds of pages requires significantly more computational power. Responses will take longer to generate compared to simple chat prompts, but the overall time saved compared to manual reading is still massive.